Python爬取儿童睡前故事
作为两个小女孩的爸爸,晚上哄女儿睡觉的时候是要给她们讲故事滴,但是每次在网上搜索儿童故事都很难受,各种广告充斥,要么就是收费app,所以就想着自己利用爬虫爬取一些儿童故事,然后存储到MySQL数据库,再通过Java后台写接口,然后再开发一个小app,然后晚上就可以拿着自己手机用着自己的app,给女儿们讲故事了.
正文开始:
1. 开发环境简介:
- 操作系统: Windows10专业版
- 开发工具: Pycharm2018.3
- Python版本: 3.7
2. 爬取网站选取及分析:
2.1 网站选择:
网上找了一番之后选定了网站:贝瓦故事,选定的是里面的睡前故事
2.2 爬取网站分析:
使用谷歌浏览器访问 睡前故事网址, 通过浏览器界面可以看出在页面最下方有页数,而我们的浏览器访问睡前故事的URL地址里最后面有一个/1,点击下面的2 3 4 5页,会发现每次都是URL的最后一位进行变化,说明此网站的页面跳转就是在URL地址最后改变数字为当前的页面即可,那么我们确定了一个路线,首先在第一个页面爬取的时候需要获取到一共有多少页的页面需要爬取,然后爬取每页的故事即可.
2.3 使用工具前期准备:
大致分析了我们需要做的事情,但是在代码开始之前我们首先需要通过一些工具来进行一些前期准备工作,并在准备工作进行的时候大致选取一些可能开发中的Python类库,使得我们在编码的时候可以更从容.
在Python的爬虫开发中,有很多种方式从网页源码中获取到我们想要的内容,比如使用正则表达式获取,用xpath获取等,而我个人觉得xpath比较好用,而且在谷歌浏览器插件种就有xpath的工具,可以很直观的看到你的表达式是否可以正确的获取到你想要获取到的东西.
2.3.1 获取到故事的总页数
使用谷歌浏览器打开 睡前故事网址,然后右键点击检查
在通过下面截图的步骤进行操作
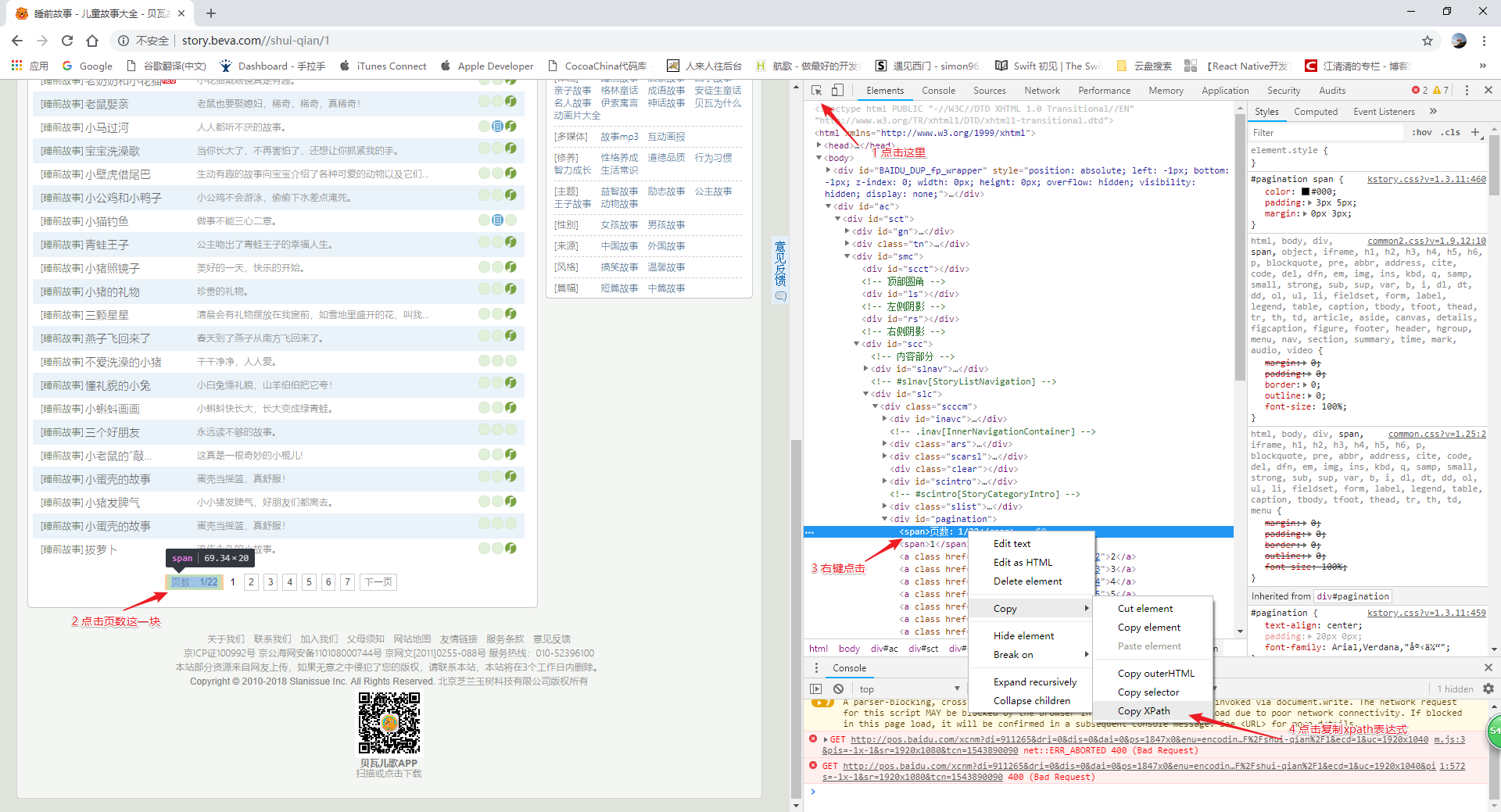
这样我们复制了一个xpath的表达式,但是还是需要测试一下这个表达式是否正确
如果你的谷歌浏览器安装过xpath helper插件,那么就直接点击即可使用,如果没有安装的话,就安装一下:

安装后了之后在我们刚才的界面打开使用
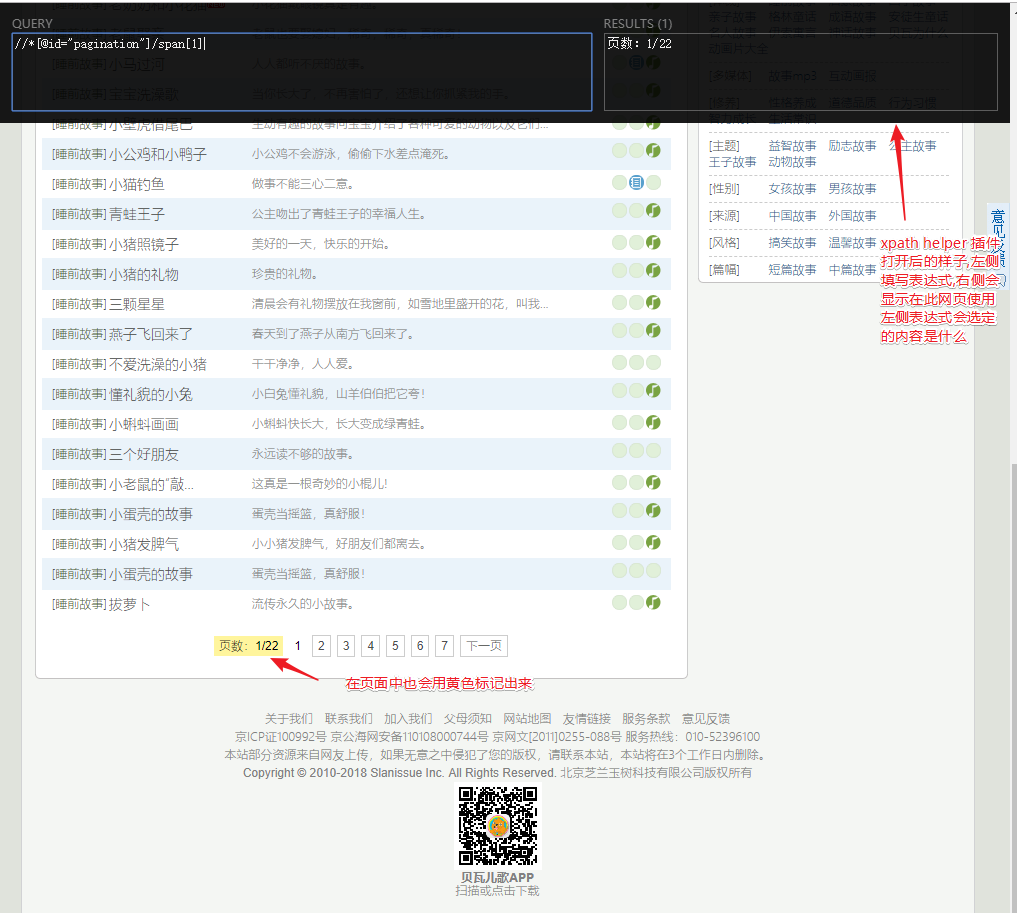
此时我们已经获取到总页数了,但是这里有个问题,通过xpath表达式拿到的其实是xpath element属性,在python中是不支持的,所以这里表达式应该要能取到文字,使其转化为python 的 str类型, 所以完整表达式应该为
//*[@id='pagination']/span[1]/text()2.3.2 获取当前页的所有故事
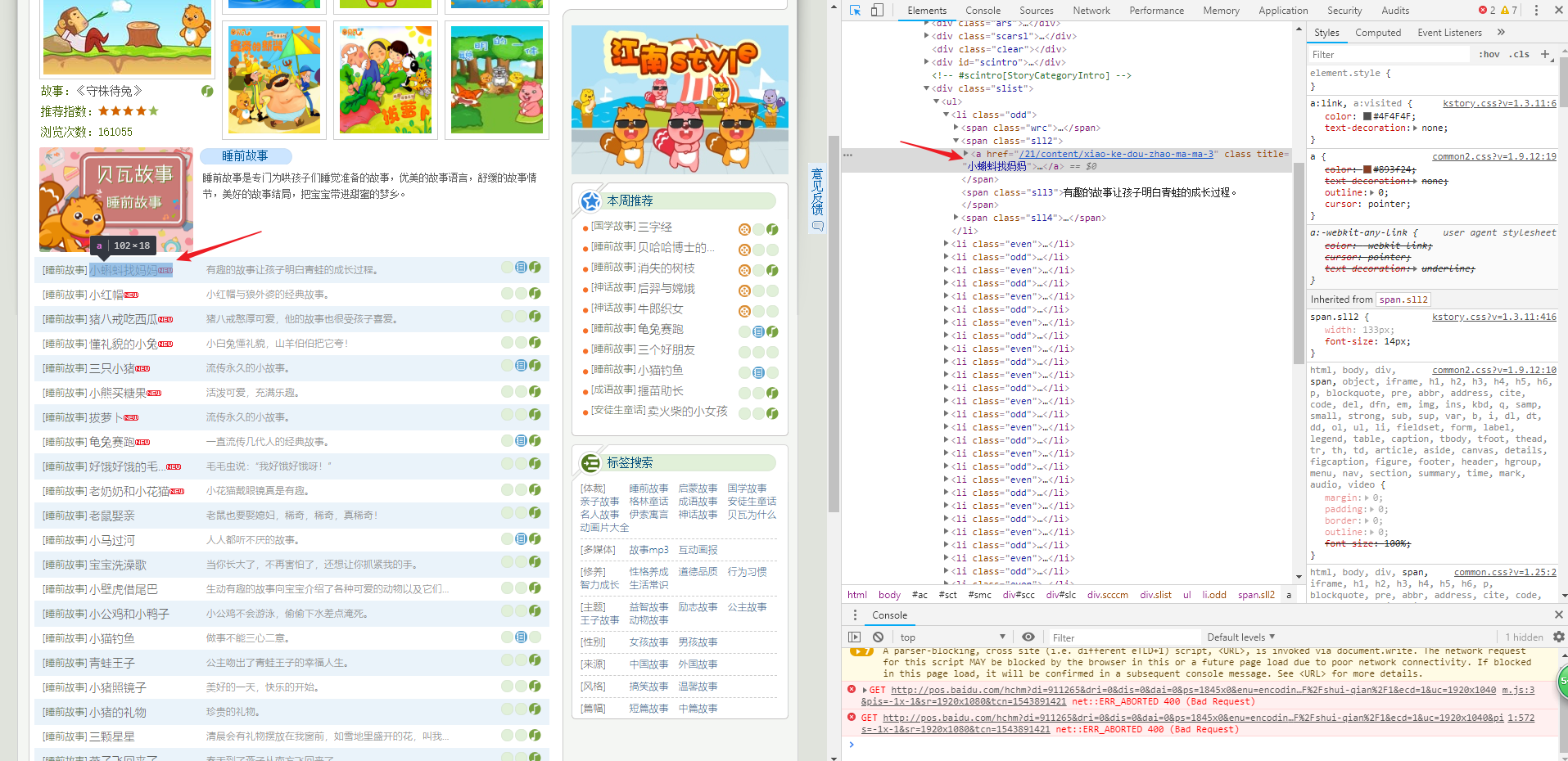
通过刚才类似的方式我们可以获取到一条,这时候我们不能只靠工具,要靠自己的xpath知识来获取到信息,我们定位到某一个故事的名称后,查找此标签的父标签,爷标签...一直找到我们想要的标签即可
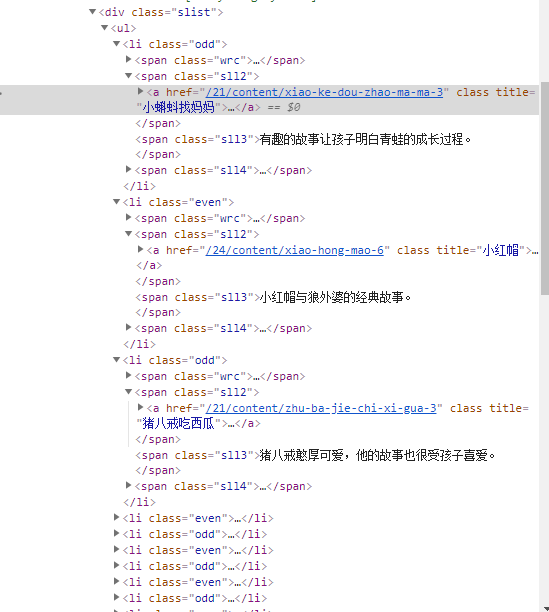
分析一下这张图:
我们想要的信息,比如故事的名称,比如故事的详情链接都在这个 span标签下,如果懂一些html语言然后结合xpath的语法,我们可以找到页面上所有的 li 标签,然后由于我们需要的内容都在一个 class为sll2的 span便签下,所以最终的xpath表达式应该为
//li//span[@class='sll2']//a/text() # 获取所有的故事的名称文字
//li//span[@class='sll2']//a/@href # 获取所有的故事详情的url然后我们验证下:
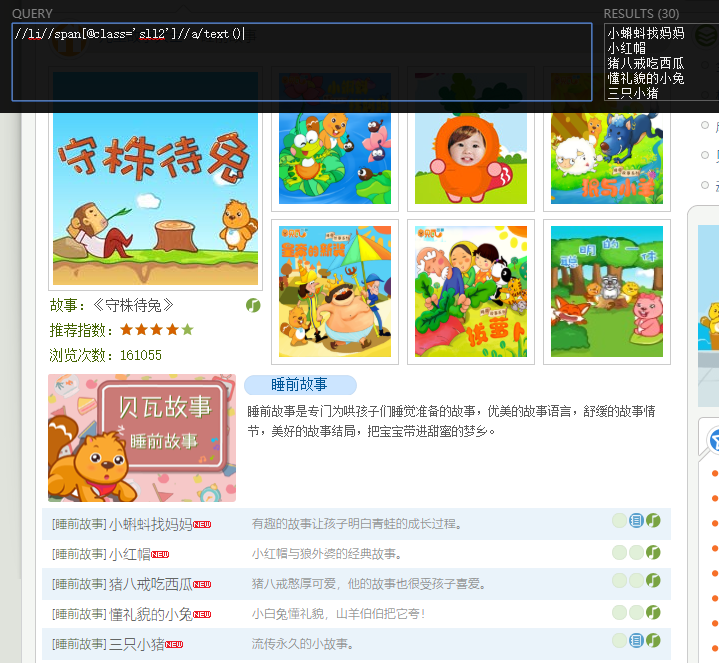

由图可以看出,我们的表达式写对了.
#### 2.3.3 获取故事的详情
随意点击一个故事进入到故事详情界面
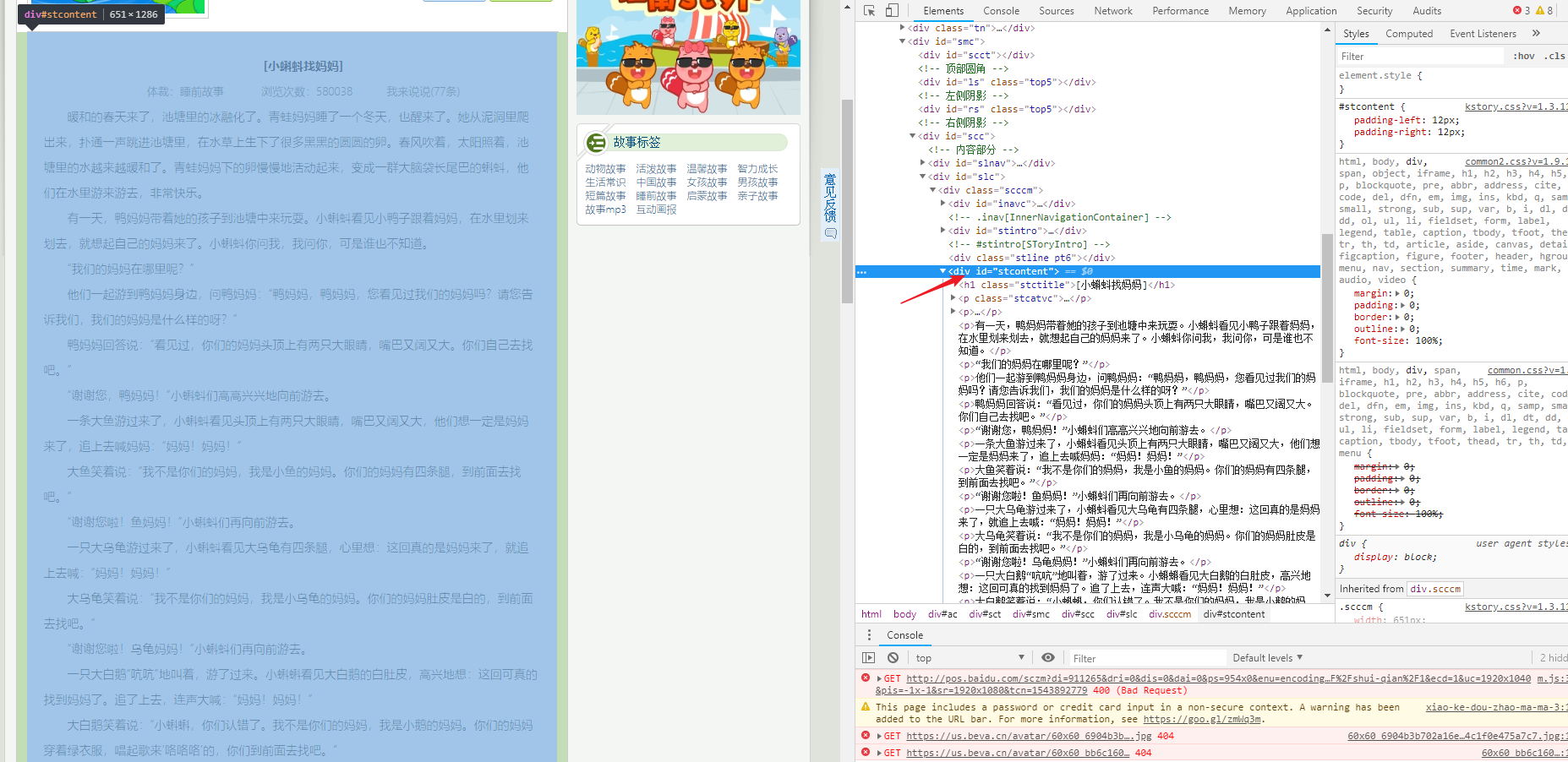
由图可以看出,id 为stcontent的div包含着所有的故事内容,而 div第一个子标签 h1 是故事的名字, 第一个p标签这是体裁啊 阅读数等属性的,这个我们暂时不需要,我们需要的是除去第一个p标签之外的所有的p标签就是故事的内容了,所以我们的故事的的详情xpath表达式应该为:
//*[@id='stcontent']/p[position()>1]/text()验证一下:
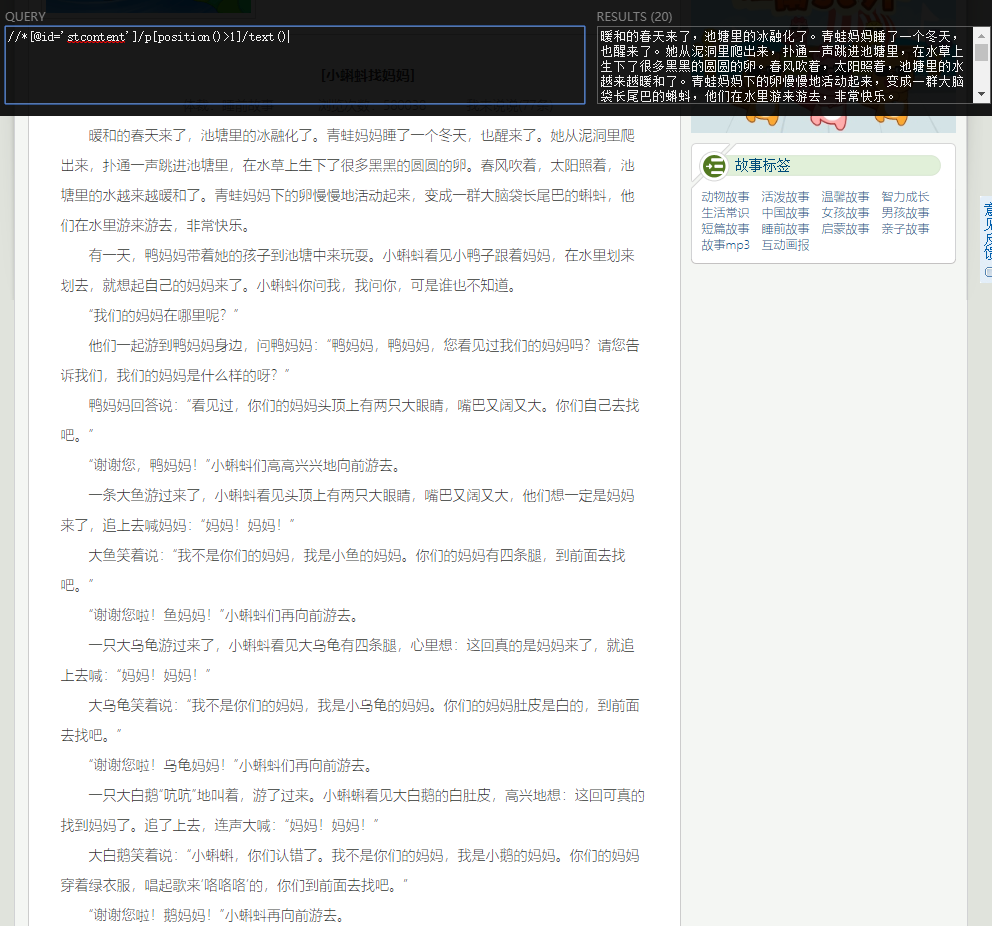
网页本体不标黄是因为加上了/text()
以上,基本上所有的需要获取的信息都拿到了.下面开始开始代码伺候.
3 代码实现
3.1 使用的库的准备:
- 网络请求库: requests
- xpath库: lxml
- 数据库存储库: pymysql
这些库可以使用Pip安装,我使用的是pycharm,可以直接通过ide安装,具体看图:
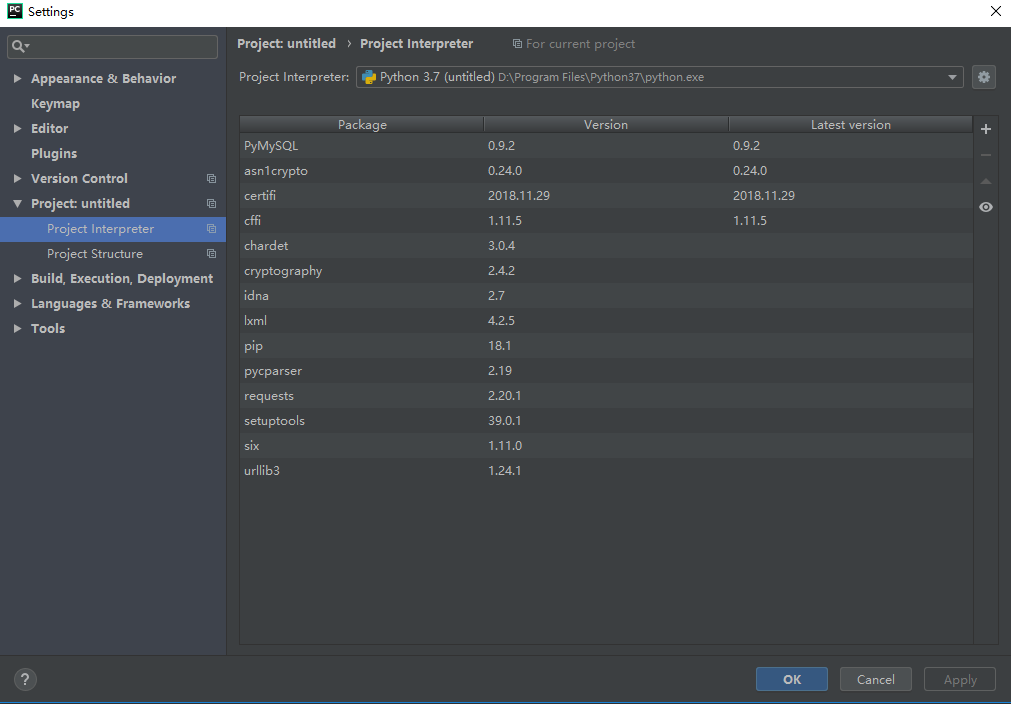
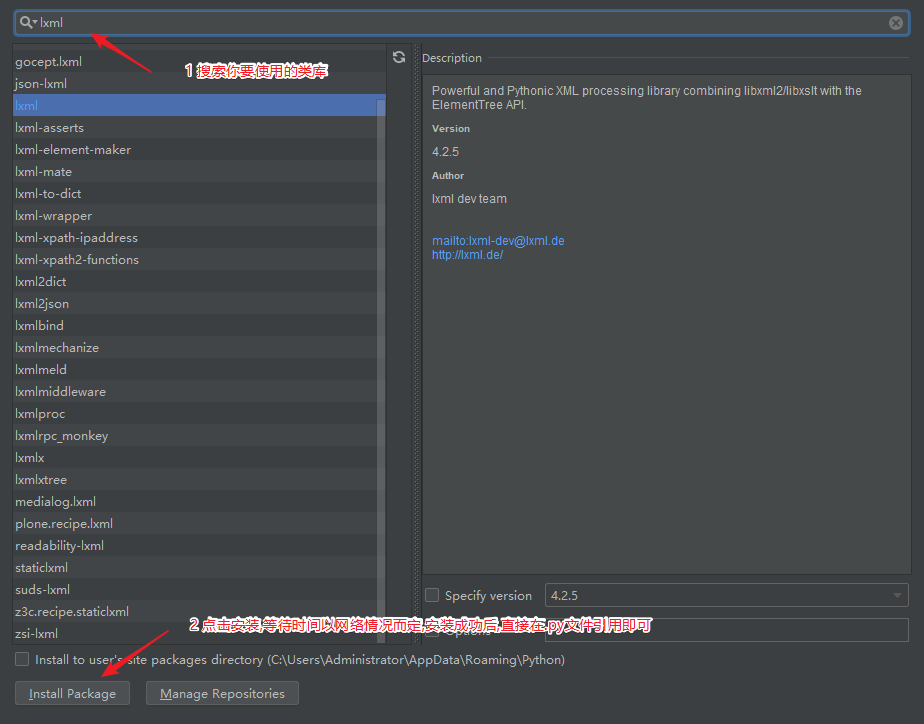
其他使用类库同理安装.
3.2 代码中引用库
from lxml import etree
import requests
import pymysql3.3 创建工具方法
由于此爬虫需要爬取大约600多个页面,所以我们写一个工具类,传入URL地址,返回一个etree可处理的类型,代码如下:
# 通过url地址获取到对应界面
def get_dom_html(self, url):
# 通过requests类库请求网页数据,然后交由xpath
# 获取网页数据
html = requests.get(url).content.decode("utf-8")
# etree处理Html数据
dom_tree = etree.HTML(html)
return dom_tree3.4 获取一共需要爬取多少页故事
按照上面的分析,需要获取到需要爬取多少页的故事,代码如下:
# 获取故事有多少页
def get_pagenumbers_of_story(self, url):
dom_tree = self.get_dom_html(url)
pages_str = dom_tree.xpath("//[@id='pagination']/span[1]/text()")
# 得到的结果为 <页数:1/22>但是这里有个问题,看起来这里像是字符串,但是如果你使用截取字符串方式就会报错,这里type()一下,原来是list
# 那么就使用list的方法解决
# 由于打印出来page_str为List而且只有一个数据就是 < 页数:1/22 > 所以遍历得到字符串
list_str = ""
for s in pages_str[0]:
list_str += s
# 通过split方法,对字符串进行切片,得到一个list, list有两个数据,/ 左侧的(页数:1) 和 /右侧的(22),通过下标取到22 并且转为int
return int(list_str.split("/")[1])3.5 获取每一页中故事的名字及故事的详情url
按照上面分析,需要获取到每页的故事的名字及故事详情,代码如下:
# 通过当前界面请求获取到所有的故事的名字以及故事详情的url地址
def get_story_info_for_page(self, page):
#数组申明,用于存储每个故事的名称、链接以及详情字典
page_store_info = []
dom_tree = self.get_dom_html(self.first_page_url + "/" + str(page))
print("正在请求第" + str(page) + "页");
# name_list用于存储所有的名字
name_list = dom_tree.xpath("//li//span[@class='sll2']//a/text()")
# sub_url_list用于存储所有的故事详情的链接
sub_url_list = dom_tree.xpath("//li//span[@class='sll2']//a/@href")
# name_list与sub_url_list长度相同,所以直接循环其中一个
for i in range(len(name_list)):
#通过get_story_content方法获取到每个故事的详情
story_content = self.get_story_content(self.base_url + sub_url_list[i])
print("正在请求第" + str(page) + "个页面中的" + name_list[i])
# 把名字 链接 故事详情放入到字典中保存
dict = {"story_name": name_list[i],
"story_url": self.base_url + sub_url_list[i],
"story_content": story_content}
# 每页的字典存储到对应页故事的数组中
page_store_info.append(dict)
return page_store_info3.6 获取故事详情
按照上面分析,需要获取到每个故事的详情,代码如下:
def get_story_content(self, url):
story_content = ""
dom_tree = self.get_dom_html(url)
# 通过xpath表达式获取到故事详情 获取到的文字是一个list
story_content_list = dom_tree.xpath("//*[@id='stcontent']/p[position()>1]/text()")
# 由于获取的文字没有段落,通过list循环在每个p标签的文字后增加换行符
for index in range(0, len(story_content_list)):
story_content = story_content + story_content_list[index] + "\n"
return story_content3.7 获取到所有的故事后,保存到数据库
def run(self):
# 获取总共有多少页故事
pages = self.get_pagenumbers_of_story(self.first_page_url)
# 根据页数进行循环请求
for page in range(1, pages):
# 通过get_story_info_for_page获取到每页的数据放入page_story_info中存储
page_story_info = self.get_story_info_for_page(page)
# 把每页的数据数组放入到总数组中
self.story_info.append(page_story_info)
# 存储到数据库
# 1 获取数据库连接:
db_connection = pymysql.connect(host='localhost',
user='root',
password='root',
db='python_spider_stories')
# 2 获取会话指针
cursor = db_connection.cursor()
# 总数组中存储了每页的字典数组,所以进行双层循环
for l_list in self.story_info:
# 循环每页数组得到字典
for story_dict in l_list:
story_name = story_dict["story_name"]
story_url = story_dict["story_url"]
story_content = story_dict["story_content"]
# 3 执行sql语句
cursor.execute("insert into stories(story_name, story_url, story_content) value(%s,
%s, %s)", (story_name, story_url, story_content))
# 4 commit
db_connection.commit()
# 5 关闭数据库
db_connection.close()代码中,我尽量多写了注释,可能在设计模式上以及封装上还有一些问题,但是也算是第一个练手的Python爬虫,爬取时候截图:
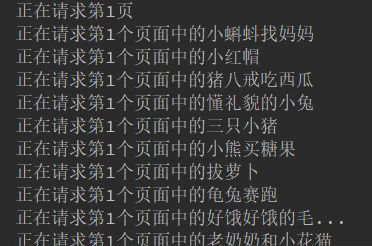
数据库中数据截图:
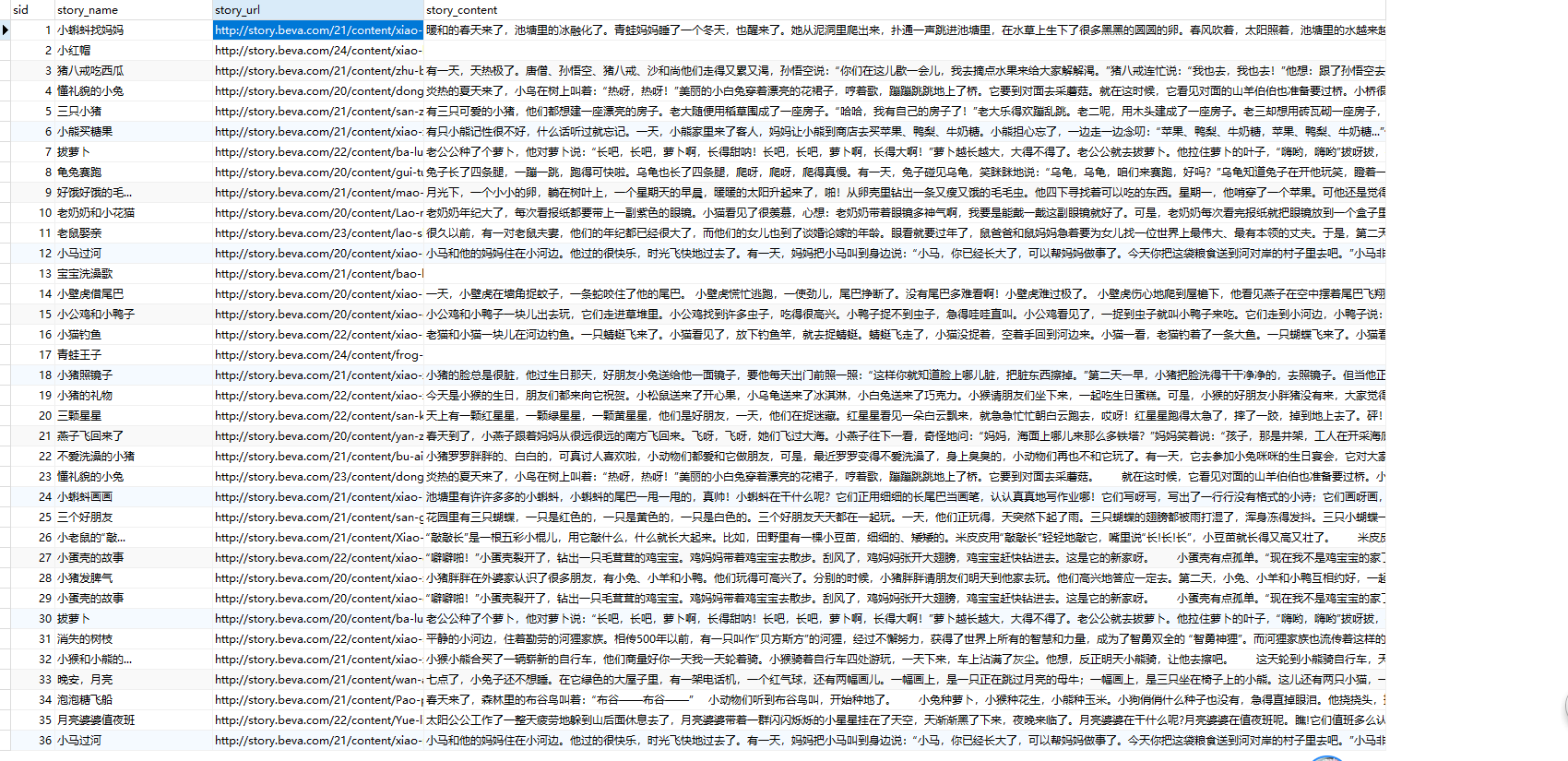
一些空白的,我看了一下,是详情页中不是直接就有详情的,后期我再研究更改一下代码吧.
代码文件共享出来,地址是 请点我
本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。