1. 题目:
随机生成2W个数字,打印出前五个最大的数字
2. 思路:
①: 首先需要随机生成20000个数字
②: 先使用冒牌排序求出结果
③: 使用更好的算法求出结果
④: 对比两者所耗时间
3. 代码:
3.1 随机生成随机数的方法实现:
// 根据传入的个数获取随机数,参数n为要获取的随机数的个数
void getData(int n)
{
// 获取文件指针
FILE* fp;
// 提前申明错误的变量来存储失败的错误原因
errno_t err;
// fopen_s用来打开一个文件,此方法比fopen,_wfopen在安全性上都有增强。
/*
方法有三个参数
pFile 文件指针将接收到打开的文件指针指向的指针。
infilename 文件名
inmode 允许的访问类型
返回值: 如果成功返回0
失败有很多可能,自行百度
*/
err = fopen_s(&fp, "data.txt", "w");
if (err == 0 && fp != NULL)
{
//srand函数是随机数发生器的初始化函数。原型:void srand(unsigned int seed);srand和rand()配合使用产生伪随机数序列
srand(1);
for (int i = 0; i < n; i++)
{
// fprintf是C/C++中的一个格式化库函数,位于头文件<cstdio>中,其作用是格式化输出到一个流文件中
/**
函数原型:
int fprintf (FILE* stream, const char*format, [argument])
参数:
stream-- 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
format-- 这是 C 字符串,包含了要被写入到流 stream 中的文本。它可以包含嵌入的 format 标签,format 标签可被随后的附加参数中指定的值替换, 并按需求进行格式化。format 标签属性是%[flags][width][.precision][length]specifier
[argument]-- 这里插入的是生成的伪随机数
*/
fprintf(fp, "%d\n", rand());
}
// close是一个函数名,功能是关闭一个流
fclose(fp);
}
}
3.2 冒泡排序:
通过3.1的方法,可以获取到传入个数的随机数,并且在项目目录里可找到一个存储这些数字的名为data.txt的文件,打开即可看到所生成的所有随机数。
那么下一步就编写冒泡排序求出结果;代码如下:
// 冒泡排序
void solutionOne(int n)
{
FILE* fp;
errno_t err;
// 申明数组并初始化数组所有元素为0
int a[200000] = { 0 };
err = fopen_s(&fp, "data.txt", "r");
if (err == 0 && fp != NULL)
{
// 读取并存储在数组中
for (int i = 0; i < n; i++)
{
// fscanf 函数原型为 int fscanf(FILE * stream, const char * format, [argument...]); 其功能为根据数据格式(format),从输入流 (stream)中读入数据,存储到argument中,遇到空格和换行时结束。fscanf位于C标准库头文件<stdio.h>中。
/*
stream-- 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
format-- 这是 C 字符串,包含了以下各项中的一个或多个:空格字符、非空格字符和format 说明符。 format 说明符形式为[=%[*][width] [modifiers]type=]
[argument...]-- 下标位置,使用了a + i ,众所周知,数组的地址即数组首个元素的内存地址,然后for循环增加i,故第三个参数传入的是每个元素的地址
*/
fscanf_s(fp, "%d", a + i);
}
fclose(fp);
}
// 冒泡排序
for (int loop = 0; loop < n; loop++)
{
for (int i = 0; i < n - loop; i++)
{
if (a[i] < a[i + 1])
{
int temp = a[i];
a[i] = a[i + 1];
a[i + 1] = temp;
}
}
}
// 打印出五个最大的数字
if (n >= 5)
{
for (int i = 0; i < 5; i++)
{
cout << a[i] << endl;
}
}
}
3.3 使用更好的算法求出结果:
// 边读边比
void solutionTwo(int n)
{
// 由于题目要求找到最大的五个数字,所以这里申明一个个数为5的数组,并初始化所有元素为0
int a[5] = {0};
// 存储数组a中元素的个数
int cnt = 0;
FILE* fp;
errno_t err;
err = fopen_s(&fp, "data.txt", "r");
if (err == 0 && fp != NULL)
{
// 读入
for (int i = 0; i < n; i++)
{
int val = 0;
// 依次读取文件数据,并且存在val中
fscanf_s(fp, "%d", &val);
// 如果cnt小于5,则说明数组未被读取的数字写满
if (cnt < 5)
{
// 依次写入
a[cnt++] = val;
}
else
{
//大于5则说明数组写满了,这时候就需要进行元素大小的对比
// 初始化两个变量, min代表所有数字中最小的数字,minIndex是最小数字在数组中的下标
int min = 9999999, minIndex = -1;
// 先通过数组内的循环拿到最小的数字及最小数字在数组中的下标
for (int i = 0; i < 5; i++)
{
if (a[i] < min)
{
min = a[i];
minIndex = i;
}
}
// 然后对比读取的数字是否大于数组中最小的数字,如果大于就替换数组中最小的数字
if (val > min)
{
a[minIndex] = val;
}
}
}
fclose(fp);
}
// 再通过冒泡排序进行大小排序
for (int loop = 1; loop < 5; loop++)
{
for (int i = 0; i < 5 - loop; i++)
{
if (a[i] < a[i + 1])
{
int temp = a[i];
a[i] = a[i + 1];
a[i + 1] = temp;
}
}
}
for (int i = 0; i < 5; i++)
{
cout << a[i] << endl;
}
}
3.4 对比两者所耗时间:
int main()
{
int dataNum = 20000;
getData(dataNum);
clock_t start, end;
start = clock();
solutionOne(dataNum);
end = clock();
cout << "方案1使用了" << (end - start) * 1000 / CLOCKS_PER_SEC << "ms" << endl;
start = clock();
solutionTwo(dataNum);
end = clock();
cout << "方案2使用了" << (end - start) * 1000 / CLOCKS_PER_SEC << "ms" << endl;
}
运行结果:
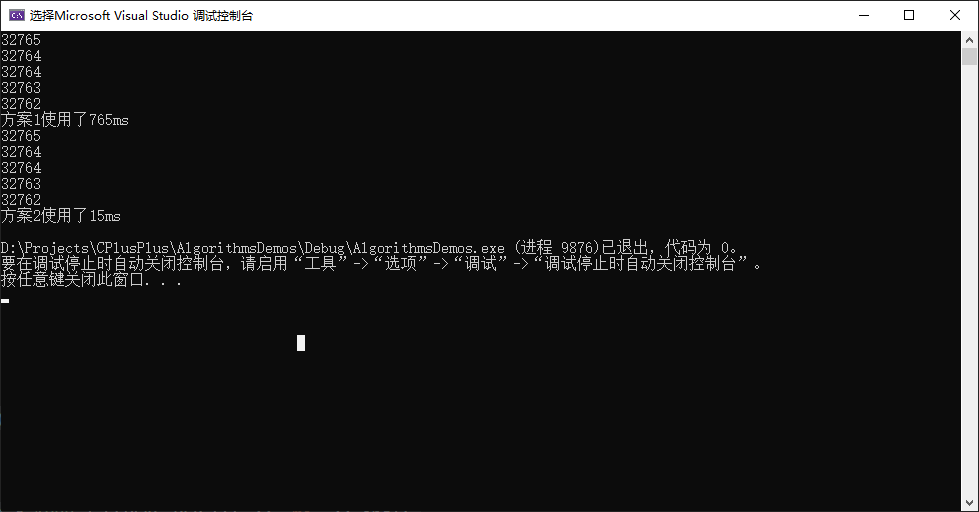
以上结果可看出,通过算法的优化,性能是可以大大的提升的。